Workflow
Overview
Workflow is a feature that allow you can use some pre-defined functions to complete some tasks. For example, you can use ExternalBuildIndex workflow to build index externally for your Postgres cluster. There are some advantages of using workflow:
- Out Of Box: You can use the pre-defined functions to complete some tasks without writing any code.
- Accelerate Tasks: You can use a server with a higher resource configuration than the PostgreSQL cluster to accelerate the task.
- Cluster Stability: The workflow is executed in a separate server, which will not affect the stability of the PostgreSQL cluster.
- Low Cost: You do not need to pay continuously like a database for high configuration resources for short-term tasks.
Supported Workflows
Supported workflows are as follows:
ExternalBuildIndex
The ExternalBuildIndex workflow is used to build vchord index externally for your Postgres cluster, details can be found here.
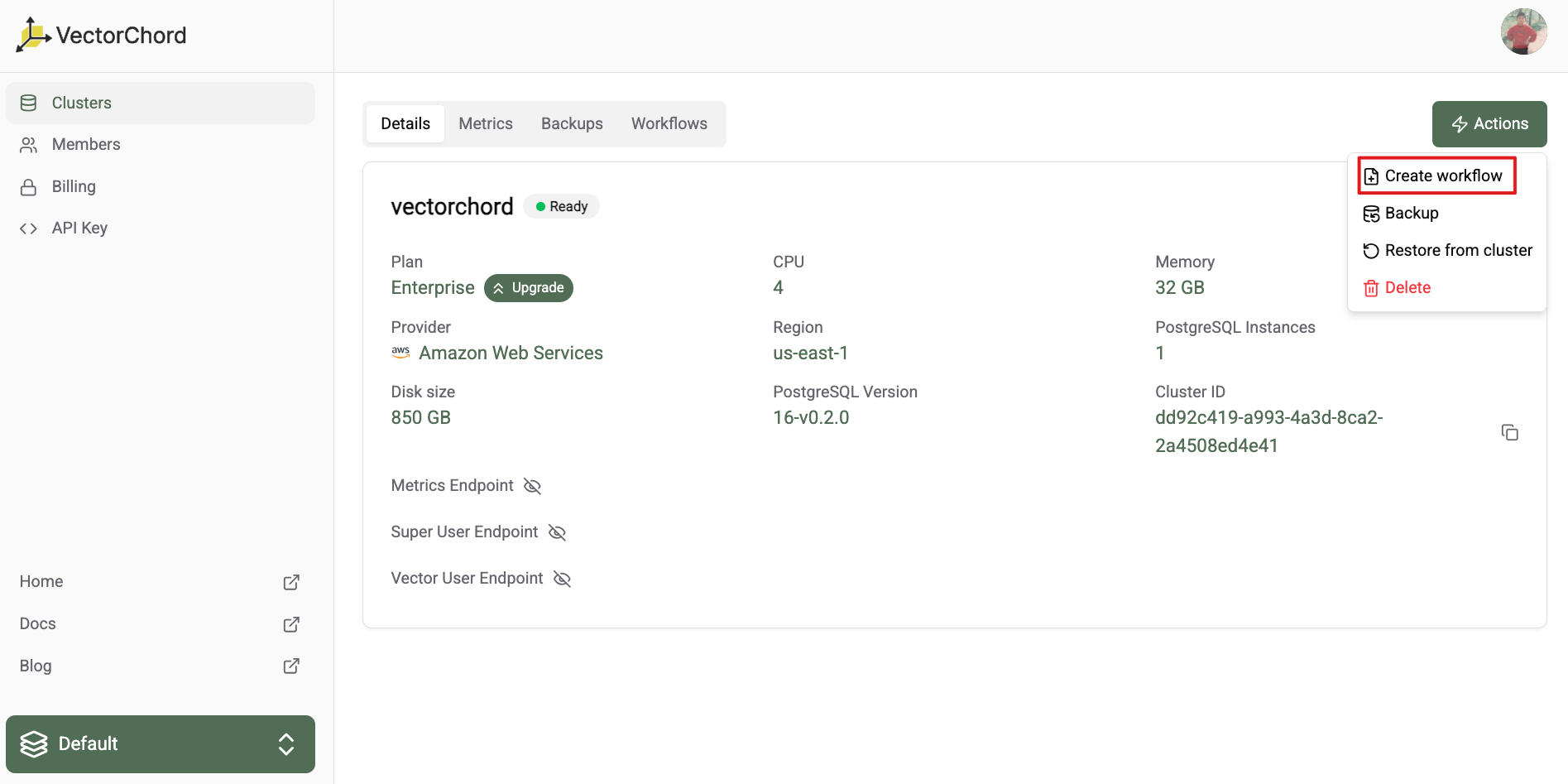
In dashboard, you can click the Create Workflow button to create a new workflow.
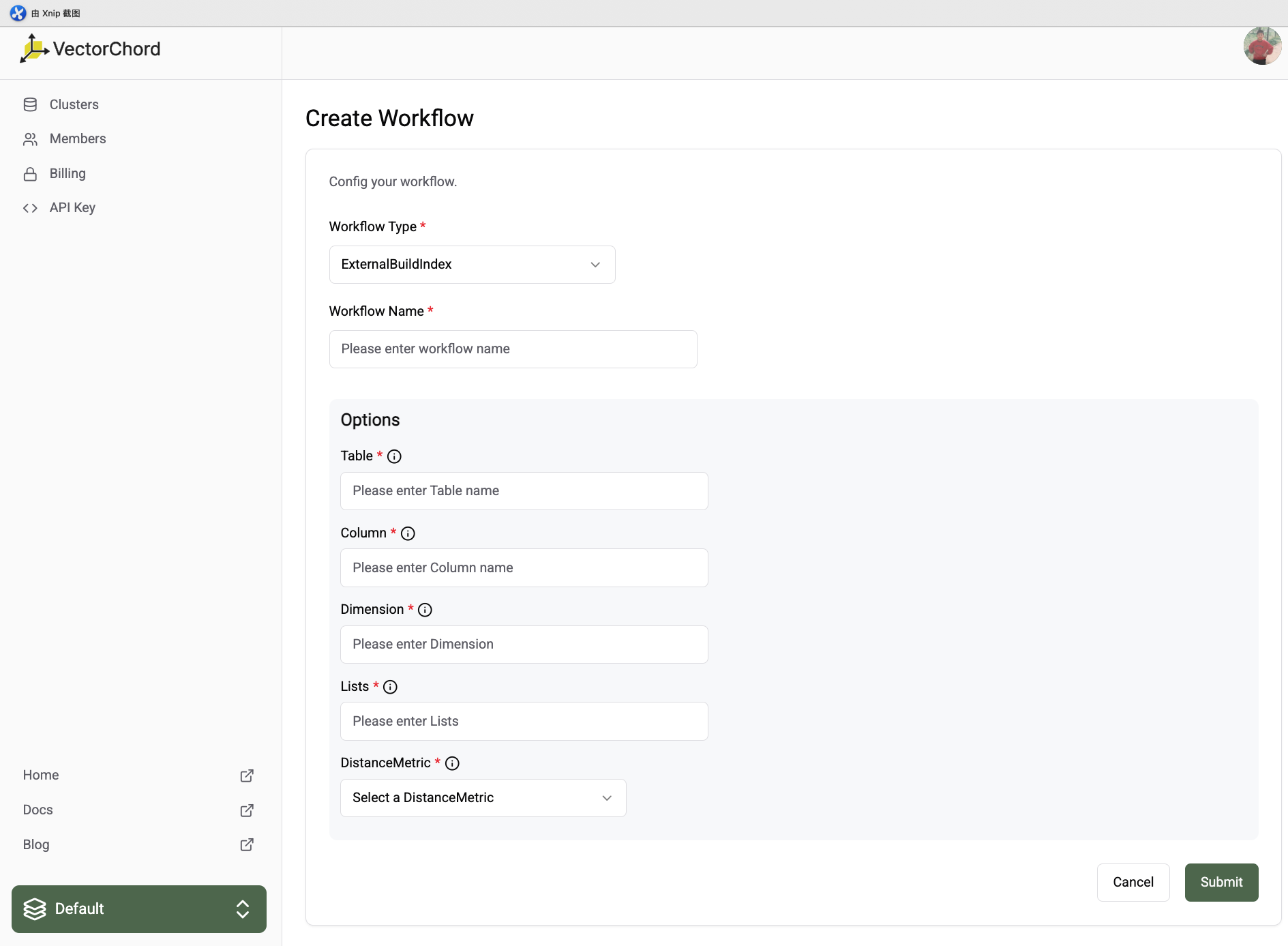
You need to specify the following information:
- Workflow Name: A unique name for your workflow.
- Option: The option for
ExternalBuildIndexworkflow- Table: The table where the vector is located
- Column: Vector column name
- Dimension: The dimension of the vector
- Lists: KMeans n list
- DistanceMetric: The distance metric for the vector
- DistanceMetricCosine: Cosine distance
- DistanceMetricL2: Euclidean distance
- DistanceMetricDot: Dot product distance
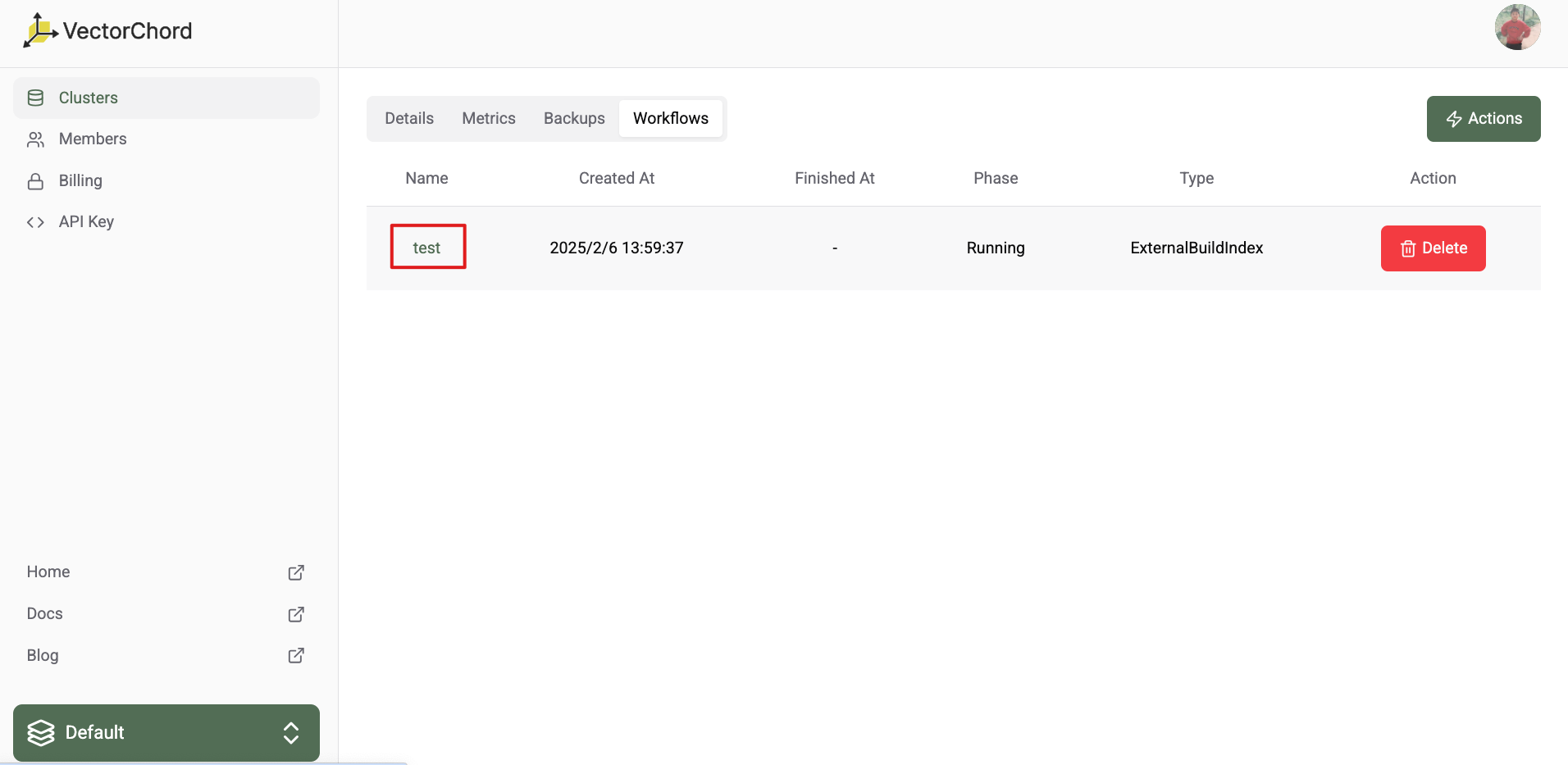
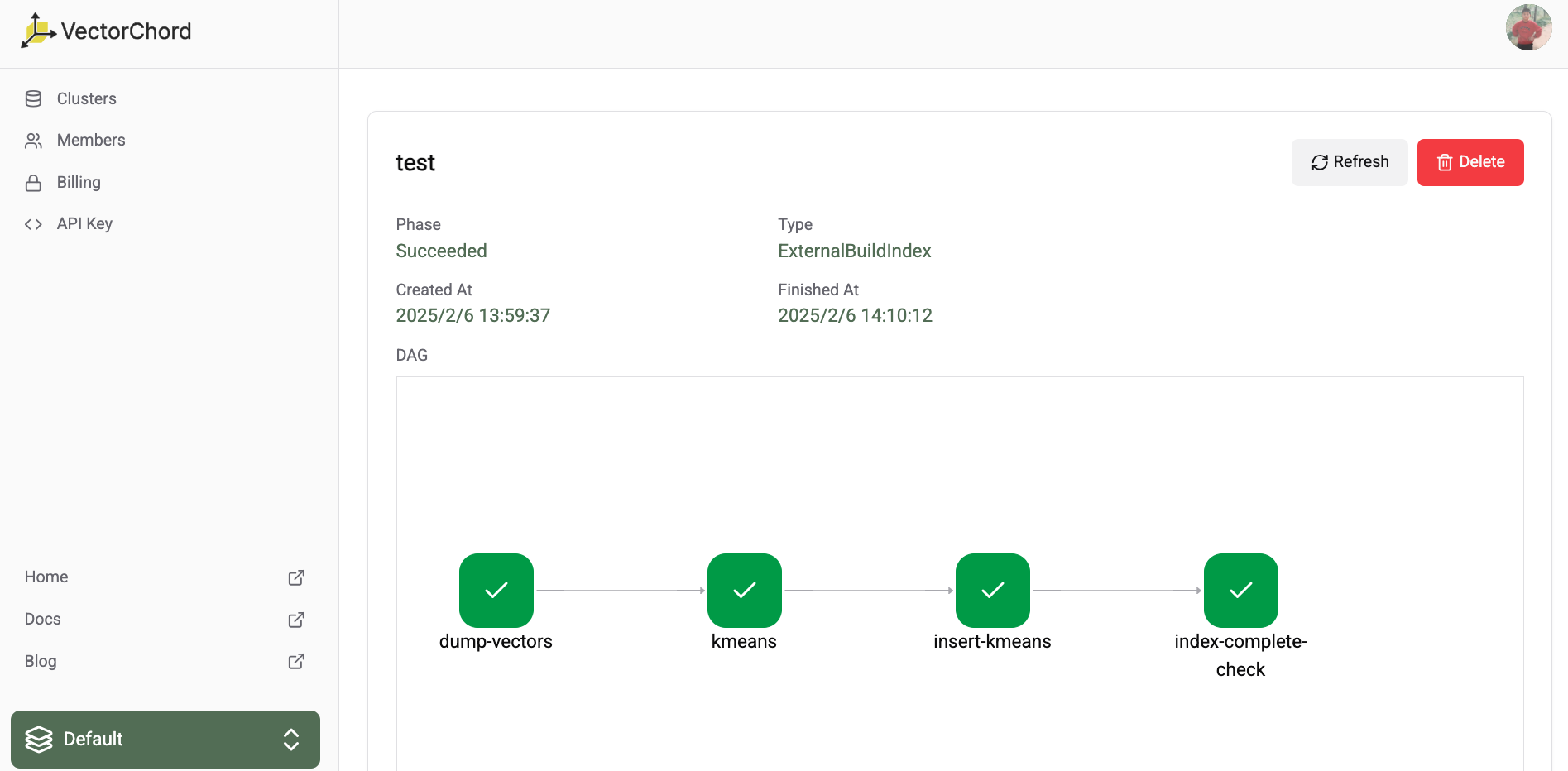
After submitting the workflow, the workflow will be in the Running status. The workflow will be unavailable during the running process. The running process may take a few minutes to complete. After the running process is completed, the workflow will be in the Succeeded status. You can list all the workflows in the dashboard.
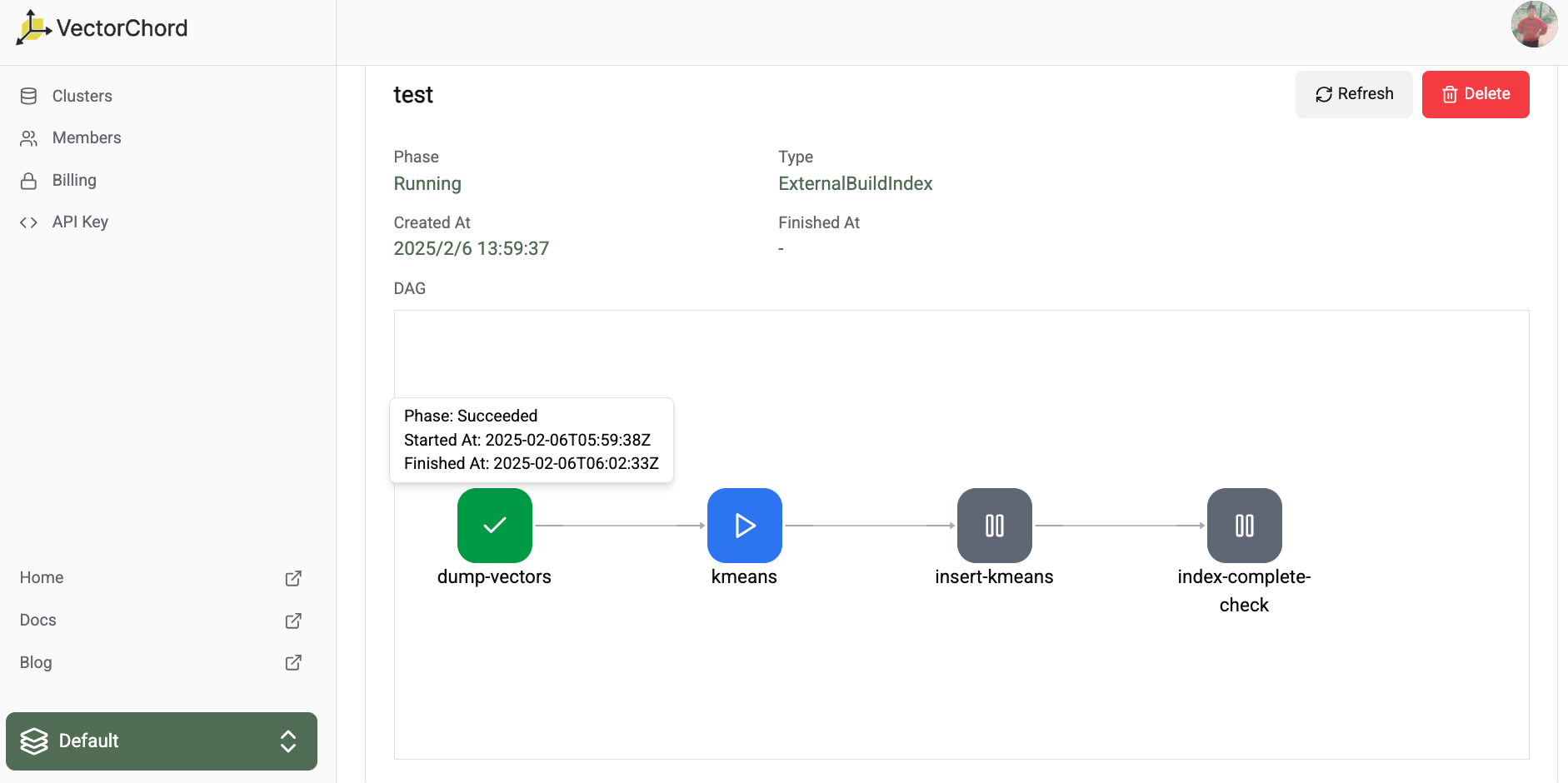
You can check the detail of every step in the workflow detail page.
When the workflow is in the Succeeded status, you can validate the index is ready to use.
$ psql 'postgres://vectorchord_user:C8bTXXFi2vxA@vectorchord-oews3hvirnsq3vi7.us-east-1-dev.aws.vectorchord.com:5432/vectorchord?sslmode=require'
psql (15.3, server 16.5)
WARNING: psql major version 15, server major version 16.
Some psql features might not work.
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
vectorchord=# EXPLAIN ANALYZE SELECT * FROM sift ORDER BY embedding <-> '[12,47,14,25,2,3,4,7,14,122,90,7,0,0,6,14,0,24,122,22,2,4,6,0,0,10,93,10,6,6,0,0,122,31,9,23,19,9,8,56,122,100,29,19,3,0,0,25,3,9,43,59,76,32,0,0,8,6,10,7,24,58,1,1,81,23,32,68,14,19,10,23,122,13,2,1,4,9,86,122,3,0,0,8,122,95,68,30,9,2,0,2,26,50,44,13,0,0,0,3,12,82,18,7,6,0,0,0,2,20,112,122,6,5,1,0,3,69,122,43,15,1,0,0,0,27,29,21]' LIMIT 5;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..1.85 rows=5 width=532) (actual time=0.644..0.683 rows=5 loops=1)
-> Index Scan using sift_embedding_idx on sift (cost=0.00..73962.25 rows=200012 width=532) (actual time=0.643..0.681 rows=5 loops=1)
Order By: (embedding <-> '[12,47,14,25,2,3,4,7,14,122,90,7,0,0,6,14,0,24,122,22,2,4,6,0,0,10,93,10,6,6,0,0,122,31,9,23,19,9,8,56,122,100,29,19,3,0,0,25,3,9,43,59,76,32,0,0,8,6,10,7,24,58,1,1,81,23,32,68,14,19,10,23,122,13,2,1,4,9,86,122,3,0,0,8,122,95,68,30,9,2,0,2,26,50,44,13,0,0,0,3,12,82,18,7,6,0,0,0,2,20,112,122,6,5,1,0,3,69,122,43,15,1,0,0,0,27,29,21]'::vector)
Planning Time: 0.069 ms
Execution Time: 0.710 ms
(5 rows)