Hybrid search with Postgres Native BM25 and VectorChord
In the era of RAG (Retrieval-Augmented Generation), efficiently retrieving relevant data from vast datasets is crucial for businesses and developers. Traditional keyword-based retrieval methods, such as those utilizing BM25 as a scoring mechanism, excel in ranking documents based on term frequency and exact keyword matches. This makes them highly effective for structured queries and keyword-heavy content. However, they struggle with understanding synonyms, contextual nuances, and semantic intent. Conversely, vector-based retrieval captures deep semantic meaning, enabling better generalization across varied queries but sometimes sacrificing precision in exact keyword matches. Hybrid Search bridges this gap by combining BM25’s precision with vector search’s contextual understanding, delivering faster, more accurate, and semantically aware results.
This article explores how to implement Hybrid Search in Postgres using VectorChord-bm25 for keyword-based retrieval and VectorChord for semantic search. By leveraging VectorChord-bm25's BM25 ranking with the Block-WeakAnd algorithm and VectorChord's advanced vector similarity capabilities, you can build a robust search system that seamlessly integrates keyword precision with semantic understanding. Whether you're building a recommendation engine, a document retrieval system, or an enterprise search solution, this guide will walk you through the steps to unlock the full potential of hybrid search.
All related benchmark codes can be found here.
Hybrid Search Explained
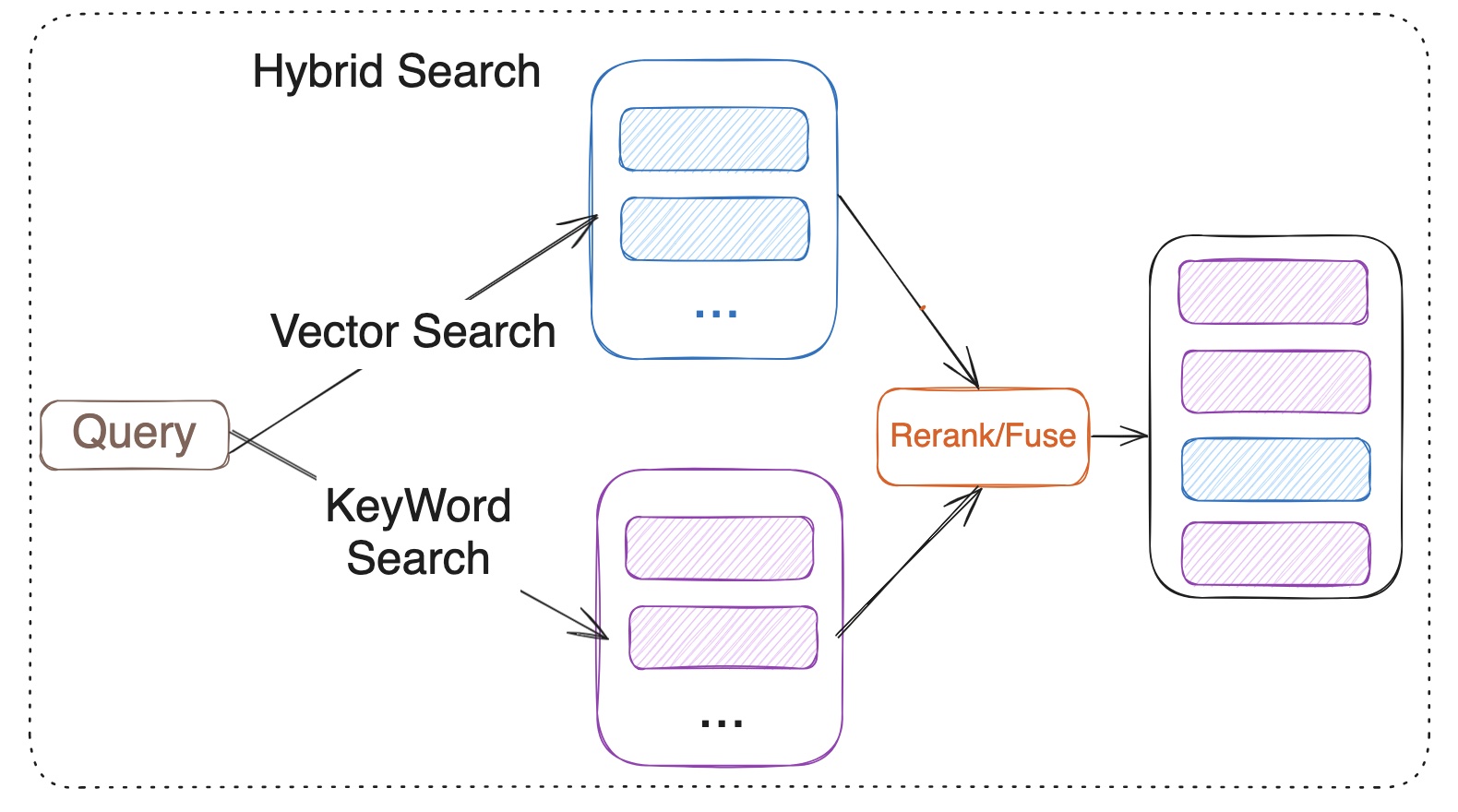
Hybrid Search merges the results from vector search and keyword search. Vector search is based on the semantic similarity between the query and the documents, while keyword search relies on the BM25 ranking algorithm. However, it is important to note that BM25 itself is only responsible for scoring documents, while the broader keyword search process also includes steps such as tokenization, indexing, and query parsing. Hybrid Search utilizes reranker or fuses the results from both methods. Fuses include RRF (Reciprocal Rank Fusion) or weighted scoring for multiple recall strategies. Model-based rerank includes cross encoder models like bge-reranker-v2-m3 and multi-vector representation model ColBERT.
What is the VectorChord?
You may be familiar with pgvector, an open-source vector similarity search extension for Postgres. However, scalable or performance-critical scenarios may require a more advanced vector search solution. VectorChord is an excellent choice.
Check out the blog post "VectorChord: Store 400k Vectors for $1 in PostgreSQL" to learn more about its motivation and design.
What is VectorChord-BM25
VectorChord-BM25 is a PostgreSQL extension for keyword search. It not only implements BM25 ranking but also includes a tokenizer and a Block-WeakAnd index to improve speed.
What is BM25?
BM25 (Best Matching 25) is a probabilistic ranking function used in information retrieval to assess how well a document matches a query. It calculates relevance scores based on term frequency (TF) and inverse document frequency (IDF), while also applying document length normalization. The formula ensures that terms appearing frequently within a document (TF) and those rare across the corpus (IDF) are appropriately weighted, improving search accuracy and relevance. IDF measures how often a word appears across the document collection. The fewer the occurrences, the higher its value. TF represents the frequency of a specific word from the query appearing in the given document. A higher TF indicates a stronger relevance between the query and the document.
Why a Postgres native BM25 Ranking implementation is needed?
In our previous blog post, VectorChord-BM25: Revolutionizing PostgreSQL Search with BM25 Ranking — 3x Faster Than Elasticsearch, my colleague Allen has already provided a detailed and sufficient explanation, which can be referred to.
Tutorial: Use VectorChord-BM25 and VectorChord implement Hybrid Search
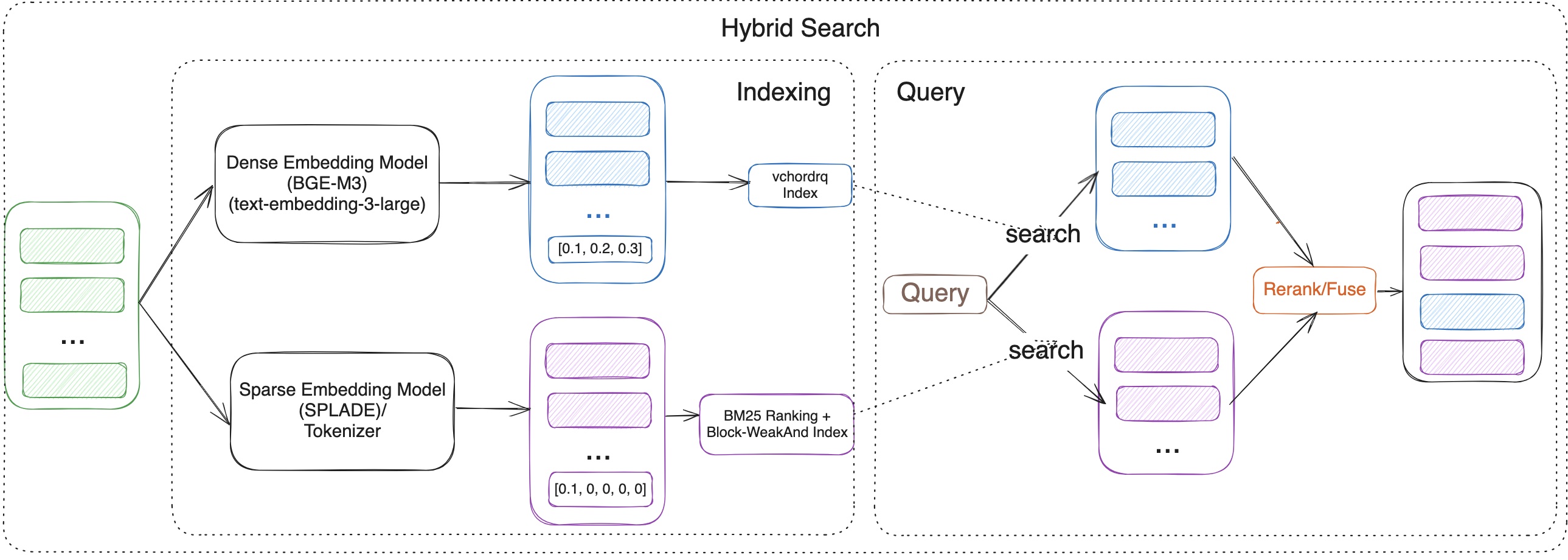
In this tutorial, we will guide you through the steps to implement Hybrid Search using VectorChord-BM25 and VectorChord in PostgreSQL. We will cover the following topics:
Semantic Search with VectorChord
Keyword Search with VectorChord-BM25
Rerank
Prerequisites
- Postgres with VectorChord-BM25 and VectorChord
If you want to reproduce the tutorial quickly, you can use the tensorchord/vchord-suite image to run multiple extensions which are provided by TensorChord.
You can run the following command to build and start the Postgres with VectorChord-BM25 and VectorChord.
docker run \
--name vchord-suite \
-e POSTGRES_PASSWORD=postgres \
-p 5432:5432 \
-d tensorchord/vchord-suite:pg17-latestCREATE EXTENSION IF NOT EXISTS vchord CASCADE;
CREATE EXTENSION IF NOT EXISTS pg_tokenizer CASCADE;
CREATE EXTENSION IF NOT EXISTS vchord_bm25 CASCADE;
\dx
pg_tokenizer | 0.1.0 | tokenizer_catalog | pg_tokenizer
vchord | 0.3.0 | public | vchord: Vector database plugin for Postgres, written in Rust, specifically designed for LLM
vchord_bm25 | 0.2.0 | bm25_catalog | vchord_bm25: A postgresql extension for bm25 ranking algorithm
vector | 0.8.0 | public | vector data type and ivfflat and hnsw access methods- Prepare the Embedding Model and Data
For embedding, we can use a pre-trained embedding model like BGE-M3 to generate embeddings for the documents. BGE-M3 is a high-quality embedding model known for its versatility in multi-functionality, multi-linguality, and multi-granularity.
For validation, we use the BEIR dataset, a heterogeneous benchmark for information retrieval. It is easy to use and allows you to evaluate your models across 15+ diverse IR datasets.
First, you need to load your data into PostgreSQL. Then you can use the following SQL query to generate embeddings for the documents.
with self.conn.cursor() as cursor:
cursor.execute(
f"CREATE TABLE IF NOT EXISTS {self.dataset}_corpus (id TEXT, text TEXT, emb vector({self.vector_dim}), bm25 bm25vector);"
)
for did, doc in tqdm(zip(doc_ids, docs), desc="insert corpus"):
emb = self.sentence_encoder.encode_doc(doc)
cursor.execute(
f"INSERT INTO {self.dataset}_corpus (id, text, emb) VALUES (%s, %s, %s)",
(did, doc, emb),
)For embedding:
from FlagEmbedding import BGEM3FlagModel
class SentenceEmbedding:
def __init__(self, model_name: str = "BAAI/bge-m3"):
self.model = BGEM3FlagModel(
model_name,
use_fp16=True,
)
def encode_docs(self, documents: list[str]):
return self.model.encode(
documents,
batch_size=32,
max_length=8192,
)['dense_vecs']The data process and embedding generation code can be found here.
Semantic Search with VectorChord
For semantic search, we utilize the RaBitQ algorithm, which is highly optimized in the VectorChord PostgreSQL extension. RaBitQ is a quantization algorithm for high-dimensional spaces, designed to improve the storage and retrieval efficiency of high-dimensional data, such as embedded vectors.
It achieves this by mapping high-dimensional vectors to a low-dimensional discrete space while preserving the similarity information of the original vectors. This process reduces storage requirements and computational costs while maintaining high retrieval accuracy.
centroids = min(4 * int(self.num**0.5), self.num // 40)
ivf_config = f"""
residual_quantization = true
[build.internal]
lists = [{centroids}]
build_threads = {workers}
spherical_centroids = false
"""
with self.conn.cursor() as cursor:
cursor.execute(f"SET max_parallel_maintenance_workers TO {workers}")
cursor.execute(f"SET max_parallel_workers TO {workers}")
cursor.execute(
f"CREATE INDEX {self.dataset}_rabitq ON {self.dataset}_corpus USING vchordrq (emb vector_l2_ops) WITH (options = $${ivf_config}$$)"
)If you find that building the index on your own dataset is too slow, you can utilize external build to accelerate the process. For more details, please refer to our previous blog: Benefits and Steps of External Centroids Building in VectorChord.
Once the index is built, you can use the following SQL query to search for similar documents:
probe = int(0.1 * min(4 * int(self.num**0.5), self.num // 40))
with self.conn.cursor() as cursor:
cursor.execute(f"SET vchordrq.probes = {probe}")
cursor.execute(
f"select q.id as qid, c.id, c.score from {self.dataset}_query q, lateral ("
f"select id, {self.dataset}_corpus.emb <-> q.emb as score from "
f"{self.dataset}_corpus order by score limit {topk}) c;"
)Key-Word Search with VectorChord-BM25
For keyword search, we need to use a tokenizer to convert the text into a BM25 vector, which is similar to a sparse vector that stores the vocabulary ID and frequency.
cursor.execute(
f"SELECT create_tokenizer('{self.dataset}_token', $$",
f"tokenizer = 'unicode'",
f"stopwords = 'nltk'",
f"table = '{self.dataset}_corpus'",
f"column = 'text'",
f"$$);"
)
cursor.execute(
f"UPDATE {self.dataset}_corpus SET bm25 = tokenize(text, '{self.dataset}_token')"
)Let me explain this operation in detail. The tokenize function is used to tokenize the text with the specified tokenizer. In this case, we used the Unicode tokenizer. The output of the tokenize function is a BM25 vector, which is a sparse vector that stores the vocabulary ID and frequency of each word in the text. For example, 1035:7 means the word with vocabulary ID 1035 appears 7 times in the text.
postgres=# select bm25 from fiqa_corpus limit 1;
-- Output: {1035:7, 1041:1, 1996:1, 1997:1, 1999:3, 2010:3, 2015:7, 2019:1, 2022:1, 2028:4, 2036:2, 2041:1, 2051:2, 2054...After creating the index, you can calculate the BM25 score between the query and the vectors. Note that the BM25 score is negative, meaning that the higher the score, the more relevant the document is. We intentionally make it negative so that you can use the default ORDER BY to retrieve the most relevant documents first.
with self.conn.cursor() as cursor:
cursor.execute(
f"SELECT q.id AS qid, c.id, c.score FROM {self.dataset}_query q, LATERAL ("
f"SELECT id, {self.dataset}_corpus.bm25 <&> to_bm25query('{self.dataset}_text_bm25', q.text , '{self.dataset}_token') AS score "
f"FROM {self.dataset}_corpus "
f"ORDER BY score "
f"LIMIT {topk}) c;"
)Rerank/Fuse
Once you obtain the results from both semantic search and keyword search, you can use a fuse or rerank process to merge the results.
- Fuse (Reciprocal Rank Fusion (RRF))
The advantage of RRF lies in its independence from specific score units; it is based on ranking for fusion, making it suitable for sorting systems with different scoring criteria.
Among them:
dis the document.nis the number of ranking systems.rankis the ranking in the sorting system.kis the adjustment parameter, the value is usually 60 (empirical value), used to control the impact of ranking on scores.
for rank, (query_id, doc_id, _) in enumerate(result, start=1):
if query_id not in rrf_scores:
rrf_scores[query_id] = {}
if doc_id not in rrf_scores[query_id]:
rrf_scores[query_id][doc_id] = 0
# Calculate and accumulate RRF scores
rrf_scores[query_id][doc_id] += 1 / (k + rank)- Cross-Encoder model Rerank
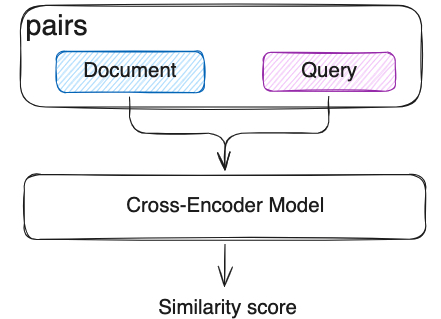
In semantic search, we already use Bi-Encoder vectorized the documents and queries separately. But this independent encoding leads to a lack of interaction between the query and the document. Cross-Encoder model will input the query and document as a whole into the model, the model will see the content of both at the same time, capturing the fine-grained semantic relationship between them through the Transformer layer. Compared with RRF, Cross-Encoder model can capture the fine-grained semantic relationship between the query and the document, and it can be more accurate but slower.
reranker = FlagReranker(
'BAAI/bge-reranker-v2-m3',
query_max_length=256,
passage_max_length=512,
use_fp16=True,
devices=["cuda:0"] # change ["cpu"] if you do not have gpu, but it will be very slow
) # Setting use_fp16 to True speeds up computation with a slight performance degradation
for query_id, docs in tqdm(results.items()):
scores = reranker.compute_score(pairs, normalize=True)
for i, doc_id in enumerate(docs):
bge_scores[query_id][doc_id] = scores[i]Evaluation
We have tested the NDCG@10 with those methods on several BEIR datasets. Here are the top10 results:
| Dataset | Semantic Search | BM25 | Cross-Encoder Rerank | RRF |
|---|---|---|---|---|
| FiQA-2018 | 0.40343 | 0.25301 | 0.42706 | 0.37632 |
| Quora | 0.88433 | 0.78687 | 0.89069 | 0.87014 |
| SCIDOCS | 0.16055 | 0.15584 | 0.17942 | 0.17299 |
| SciFact | 0.57631 | 0.68495 | 0.74635 | 0.67855 |
The table above demonstrates several conclusions:
Compared to BM25 and semantic search, the cross-encoder model rerank can significantly improve search performance across different datasets.
On some datasets, RRF may lead the performance decrease. Please conduct verification tests before deciding whether to use RRF. If effective, choosing RRF will be a very economical choice, as it is much, much faster than reranking with the cross-encoder model, and almost no resource consumption.
All related benchmark codes can be found here. If you have any questions, please feel free to contact us on Discord or email us at vectorchord-inquiry@tensorchord.ai.
Future Work
The results highlight the great potential of the hybrid search method. In the future, we will focus on the following aspects to advance RAG:
- Improve the reranking method: Explore the other model-based rerank, such as ColBERT or ColPali, to enhance reranking performance.
- Integrate graph search: Investigate the use of the Apache AGE extension for graph search and integrate it with the hybrid search method to further improve search performance.
References
- https://github.com/tensorchord/vectorChord/
- https://github.com/tensorchord/VectorChord-bm25
- https://techcommunity.microsoft.com/blog/adforpostgresql/introducing-the-graphrag-solution-for-azure-database-for-postgresql/4299871
- https://www.pinecone.io/learn/hybrid-search-intro/
- https://www.pinecone.io/learn/series/rag/rerankers/
- https://blog.vespa.ai/improving-zero-shot-ranking-with-vespa-part-two/